



こんにちは。えんどう(@ai_ec_ecaiz)です。今回は、会社で、ChatGPTなどの生成AIを導入する際に注意すべきことについて解説をします。
 えんどう
えんどうChatGPTなどの生成AIを仕事でも使いたい!会社で導入して生産性を上げたい!という方は、ぜひ参考にしてください!
注意すべきことは3つ
会社で生成AIを使えるようにする(導入する)際に注意をすべきことは2つです。
- 知的財産権を侵害しない
- 情報漏洩をしない(機密情報をChatGPTに入力をしない)
- AIを信用しすぎない
知的財産権を侵害しない
生成AIを使うということは、文章や画像、動画、音声など、なにかしらを作るということになります。その際に、他者の権利を侵害しないようにしなければいけません。
例えば「著作権」で考えてみましょう。生成AIを使って、広告用のイラスト画像を作ったとします。その作ったイラストが、第三者が著作権を持つイラストと酷似していた場合、著作権侵害になってしまう可能性があります。
もし著作権侵害だとして、著作権者に損害賠償請求をされると、裁判になったり、損害賠償を支払うなど、会社として損害が生じてしまいます。
著作権以外にも知的財産権には「特許権」「意匠権」「商標権」などがあります。また「肖像権」や「パブリシティ権」についても注意が必要です。
情報漏洩をしない(機密情報をChatGPTに入力をしない)
生成AIを使うときには「情報漏洩」にも注意が必要です。実際にSAMSUNGがChatGPTに機密情報を流出させたとして問題になりました。

SAMSUNGの事例では、いくつかの流出パターンがありますが、ChatGPTを使って会議の音声から議事録を作成するなどがありました。
なぜChatGPTを使うことで情報漏洩が起こるのか?その理由は、ChatGPTに入力された内容は記録されて、学習データとして使用されることがあるからです。学習データとして使用されるということは、ChatGPTを使っている他の誰かの生成に、あなたが入力をした情報が使われる可能性があるということになります。
そのため、会社でChatGPTなどの生成AIを利用する場合は、社外秘の情報や個人情報など、社外に漏れてはいけない情報をChatGPTで入力をしない(プロンプトに書かない、ファイルをアップロードしない)ことが重要です。
ECにおいては、社内の内部情報やECサイトのソースコード、顧客データなどを生成AIで入力することは避けましょう。
ChatGPTで会話の履歴とモデルトレーニングをオフにする
ChatGPTでの情報漏洩対策の1つとして「会話の履歴とモデルトレーニング」をオフに設定することができます。これにより、会話データをChatGPTの学習データに使われないようにすることができます。
「会話の履歴とモデルトレーニング」をオフに設定する方法は、まずChatGPTの「Settings」を開きます。
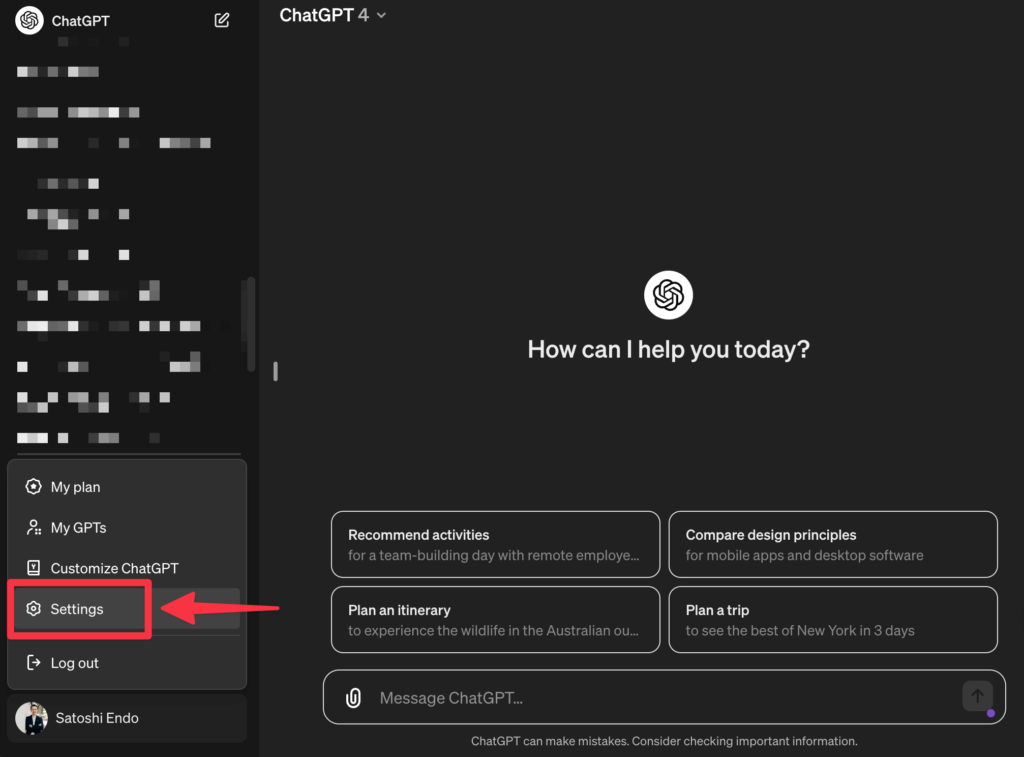
次に「Date controls」を選択して「Chat history & training」をオフ(グレーの状態)にすれば設定完了です。

- ChatGPTで「会話の履歴とモデルトレーニング」をオフに設定すると、会話の履歴が残らなくなります。
- 不正使用を監視するため、すべての会話はChatGPT側で30日間保持された後に完全に削除されます。
AIを信用しすぎない
最後に「AIを信用しすぎない」ことの大事です。生成AIで生成されるものは、必ずしも正しいということではありません。AIには「ハルシネーション(嘘をつく)」という問題もあります。
生成AIが生成したものを、そのまま信用して使うのではなく、必ず「この内容は正しいのか?」という意識を持つようにしましょう。
確認をするときには「知的財産権を侵害していないか?」も合わせて確認をするといいと思います。

